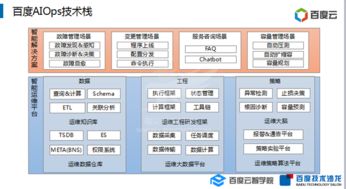
在智能推薦算法日益滲透數字生活的今天,用戶享受著前所未有的個性化內容便利,卻也深陷信息過載的漩渦。過量的、重復的、低質的信息推送不斷消耗著用戶的注意力與時間。要破解這一困局,單純優化表層推薦算法往往治標不治本。回歸根本,從數據處理與存儲支持的底層架構入手,構建高效、智能的數據服務層,是構建下一代“智慧推薦”系統、實現信息“提質減量”的關鍵路徑。
一、數據源治理:信息過載的第一道防線
信息過載的源頭,常始于數據采集的“貪婪”與“無序”。因此,必須在數據入口處建立精細化的治理策略:
- 多源數據融合與去重:整合來自用戶行為、內容屬性、社交網絡、第三方平臺等多維數據源,利用實體識別、相似度計算等技術,在數據接入層實現跨源內容的深度去重與歸一化,從根源上減少冗余信息流入系統。
- 數據質量實時評估與過濾:建立實時數據質量評估體系,對內容的原創性、權威性、完整性、時效性等維度進行打分。對于低質量、垃圾信息、虛假內容等,應在存儲前進行標記或攔截,確保存入“數據湖”或“數據倉庫”的是高價值“原料”。
- 興趣粒度分層與冷啟動優化:在數據采集時,不僅記錄用戶的顯性點擊,更應通過交互時長、完播率、深度互動等隱性信號,精細化刻畫用戶興趣的強度與穩定性。為新用戶或新內容設計專門的數據采集與快速通道,緩解冷啟動帶來的盲目推送問題。
二、存儲架構革新:支撐高效數據服務的中樞
傳統單一的存儲方案已難以應對推薦系統對海量、異構、實時數據的處理需求。面向智能推薦的存儲層需要具備以下特征:
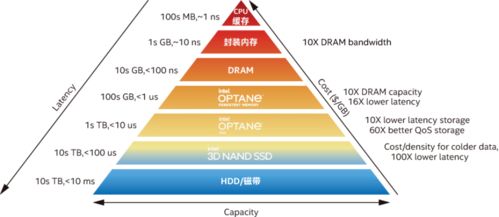
- 分層分級存儲體系:采用“熱-溫-冷”數據分層策略。將高頻訪問的用戶畫像、實時行為流、熱門內容索引存放在內存數據庫(如Redis)或高性能SSD存儲中,保障毫秒級響應;將溫數據(如近期歷史行為)存放于分布式數據庫(如HBase, Cassandra);將冷數據(如長期歸檔內容)移至成本更低的對象存儲。這種架構在保證性能的極大優化了存儲成本。
- 向量化存儲與檢索的深度集成:隨著嵌入(Embedding)技術成為推薦系統的核心,專門用于存儲和檢索高維向量數據的向量數據庫(如Milvus, Pinecone)變得至關重要。它能將用戶和內容的語義信息轉化為向量并高效存儲,支持基于相似度的毫秒級檢索,是實現“更準、更巧”推薦而非“更多”推薦的算力基礎。
- 統一的數據服務層(Data Serving Layer):在存儲層之上,構建一個抽象、統一的實時數據服務接口。無論底層數據存放在何處,推薦引擎、特征工程、在線模型都能通過這一層以一致、低延遲的方式獲取所需的用戶特征、內容特征和上下文特征。這簡化了系統復雜度,并使得數據更新(如用戶興趣漂移)能瞬間生效。
三、數據處理管道:驅動精準推薦的智能引擎
高效的數據處理管道是將原始數據轉化為推薦智能的“生產線”。
- 流批一體的特征計算:結合Apache Flink等流處理框架和Spark等批處理框架,實現特征計算的流批一體。用戶實時點擊行為可秒級更新特征,用于即時推薦;而深度畫像、模型訓練則依賴可靠的批量計算。兩者協同,確保推薦系統既敏捷又穩健。
- 自動化特征工程與元數據管理:利用自動化機器學習(AutoML)工具探索和生成有效的特征組合,并建立完善的特征元數據管理系統,追蹤特征的來源、 lineage、統計信息和效用,避免無效特征堆積造成的數據噪聲和計算浪費。
- 面向場景的模型數據倉:為不同的推薦場景(如信息流、商品推薦、視頻推薦)構建獨立的、高度優化的模型數據倉庫。每個倉庫中只存儲和計算該場景最相關的特征和數據,實現數據與計算的“垂直化”,進一步提升處理效率和推薦精度。
###
信息過載的本質,是數據處理能力與信息生產速度之間的失衡。智能推薦系統不應成為信息洪流的簡單放大器,而應成為幫助用戶甄別、篩選、匹配價值的智能過濾器。這一目標的實現,離不開一個堅實、靈活、智能的數據與存儲底層。通過源頭治理保障數據質量,通過架構革新提升服務效能,通過智能管道驅動精準計算,我們方能從數據的“礦山”中煉出真正的“金子”,讓推薦系統回歸服務用戶的本源,在紛繁的信息世界中為用戶開辟一條清澈的認知航道。