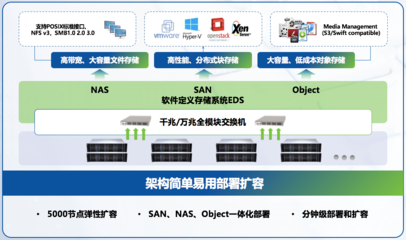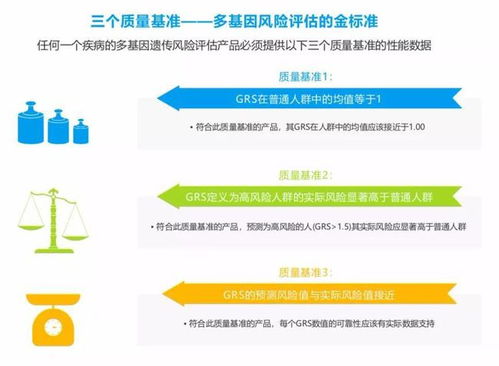
在構建大規模分布式系統時,協調、配置管理、命名服務、分布式同步和集群管理等基礎需求是不可避免的。Apache ZooKeeper作為一個開源的分布式協調服務,正是為了解決這些核心挑戰而誕生。它提供了一個簡單而強大的分布式數據存儲模型(ZNode樹),并在此基礎上構建了一系列可靠的分布式服務原語,成為眾多分布式系統(如Hadoop、HBase、Kafka等)不可或缺的“基石”。本文將深入探討ZooKeeper在數據處理與存儲支持服務方面的核心機制與價值。
一、核心數據模型:層次化命名空間(ZNode樹)
ZooKeeper的核心是一個類似于文件系統的、內存中的層次化命名空間。這個命名空間中的每個節點稱為“ZNode”。與文件系統不同,ZooKeeper的數據完全存儲在內存中,以實現高吞吐和低延遲。為了持久化,所有操作都會在事務日志和快照中記錄到磁盤。
ZNode有兩種主要類型:
- 持久節點(Persistent):創建后即存在,直到顯式刪除。
- 臨時節點(Ephemeral):與客戶端會話綁定,會話結束(連接斷開或超時)后自動刪除。這是實現服務發現和領導者選舉的關鍵。
ZNode還可以被設置為順序節點(Sequential),ZooKeeper會在其路徑后附加一個單調遞增的序列號。這在實現分布式鎖、隊列等場景中至關重要。
二、數據處理與存儲的核心特性
- 原子性保證:所有數據更新操作(
setData,create,delete)都是原子的,要么成功,要么失敗,不存在中間狀態。這確保了數據的一致性。
- 順序一致性(Sequential Consistency):來自客戶端的更新請求會嚴格按照其發送順序被應用。這是ZooKeeper最重要的保證之一,為構建更高級的同步原語奠定了基礎。
- 單一系統映像(Single System Image):無論客戶端連接到哪個服務器,都將看到相同的服務視圖。這是通過ZooKeeper的復制協議(Zab協議)實現的。
- 可靠性與高可用:ZooKeeper本身是一個分布式集群(通常由奇數個服務器組成,如3、5、7臺)。它采用基于領導者(Leader)和跟隨者(Follower)的復制模式。所有寫請求都由領導者處理并同步到多數(Quorum)節點后,才被視為成功。即使部分節點故障,只要多數節點存活,服務就依然可用。數據在集群節點間復制,具備容災能力。
- 監聽機制(Watch):客戶端可以在ZNode上設置監聽器(Watch)。當該ZNode的數據發生變化(數據更新、子節點列表變化、節點被刪除等)時,ZooKeeper會向客戶端發送一次性通知。這是一個高效的“發布-訂閱”模型,客戶端無需輪詢,從而極大地減輕了服務器和網絡的壓力,是實現配置動態更新、服務狀態監控的核心機制。
三、作為存儲支持服務的典型應用場景
基于上述數據處理能力,ZooKeeper為上層分布式系統提供了強大的支持服務:
- 配置管理(Configuration Management):將系統的全局配置(如數據庫連接串、特性開關)存儲在ZooKeeper的某個持久ZNode中。所有應用實例監聽該節點,當配置變更時,ZooKeeper會通知所有實例,實現配置的集中管理和動態推送。
- 命名服務(Naming Service):通過樹形結構,可以直觀地維護一個全局的、層次化的服務名稱到網絡地址(Endpoint)的映射。例如,Dubbo就使用ZooKeeper作為其服務注冊中心。
- 分布式鎖(Distributed Lock):利用臨時順序節點可以輕松實現排他鎖和讀寫鎖。客戶端嘗試創建代表鎖的臨時順序節點,通過判斷自己創建的節點序號是否最小來競爭鎖資源。利用監聽機制,可以高效地實現鎖的等待和獲取通知,避免了“羊群效應”。
- 集群管理與領導者選舉(Leader Election):這是ZooKeeper最經典的應用。集群中的每個實例都在同一個ZNode路徑下創建一個臨時順序節點。序號最小的節點自動成為領導者。所有其他節點監聽序號比自己稍小的節點。一旦領導者宕機(其臨時節點被刪除),下一個序號的節點會立刻收到通知并成為新的領導者。HDFS的NameNode、YARN的ResourceManager等高可用架構都依賴于此。
- 分布式隊列與屏障:通過順序節點和監聽機制,可以實現先進先出(FIFO)隊列、屏障(Barrier,等待所有成員到齊后才繼續執行)等同步原語。
- 元數據存儲:許多分布式系統使用ZooKeeper存儲關鍵的集群元數據。例如,Kafka使用ZooKeeper來存儲Broker信息、主題分區與副本的分配關系以及消費者組的偏移量(新版本已逐步遷移至Kafka內部主題)。HBase使用它來定位RegionServer和存儲元數據表(
hbase:meta)的位置。
四、使用考量與局限性
盡管強大,ZooKeeper并非萬能,使用時需注意:
- 數據容量:數據完全存儲在內存中,不適合存儲海量數據(如GB、TB級),通常用于存儲KB級別的配置、狀態和元數據。
- 寫性能:所有寫操作都需要通過領導者并達成多數派共識,因此寫吞吐量有上限。它是一個為“讀多寫少”場景優化的系統。
- “腦裂”防護:ZooKeeper的Zab協議通過嚴格的Quorum機制和領導者選舉算法,能有效避免因網絡分區導致的“腦裂”問題,保證數據一致性。
- 運維復雜度:需要維護一個奇數節點的集群,并監控其健康狀態。
###
Apache ZooKeeper通過其簡潔而嚴謹的數據模型和強大的分布式一致性保證,將復雜的分布式協調問題封裝成一系列易于使用的API。它雖然不是直接存儲業務數據的數據庫,但作為分布式系統的“神經系統”和“元數據管理中心”,在數據處理與存儲支持服務層面發揮著無可替代的作用。理解ZooKeeper的核心原理與應用模式,是設計和構建可靠、可擴展的分布式系統的關鍵一步。