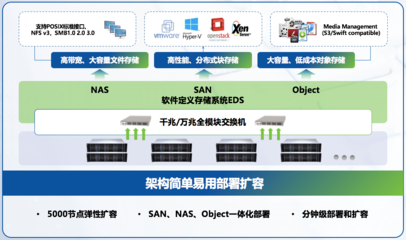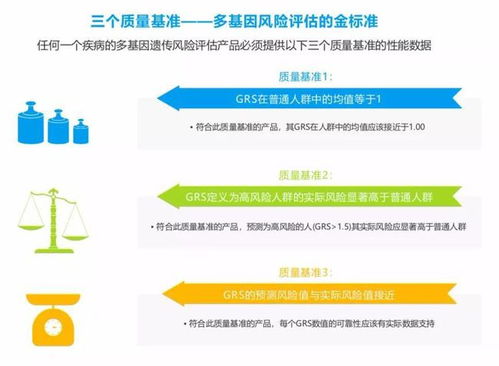
在人工智能(AI)技術日新月異的今天,模型復雜度的提升、訓練數據量的激增以及對實時推理的苛刻要求,共同指向了一個核心命題:傳統的、孤立的、靜態的數據處理與存儲模式已難以為繼。AI的下一步突破性發展,將愈發依賴于一個更智能、更高效、更協同的底層支撐體系。而“數據編排”,作為數據處理與存儲領域的關鍵演進方向,正扮演著這一支撐體系的核心角色,成為驅動AI邁向新高度的關鍵引擎。
一、AI演進對數據處理與存儲提出新挑戰
當前,AI模型的訓練與部署正面臨前所未有的數據挑戰:
- 數據規模與多樣性爆炸:從TB級到PB級甚至EB級的數據集成為常態,數據形態也從單一的結構化數據,擴展到涵蓋圖像、視頻、文本、語音、傳感器信號等多模態數據。如何高效地采集、整合、清洗如此海量且異構的數據,是首要難題。
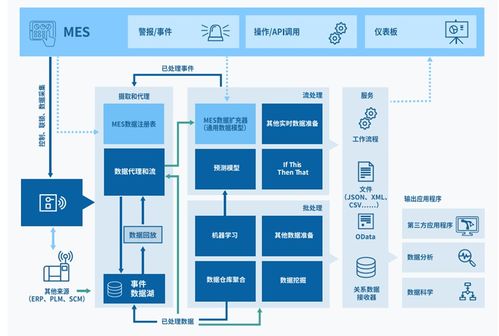
- 處理流程的復雜性與動態性:一個完整的AI數據流水線包括數據接入、預處理、標注、特征工程、模型訓練、驗證、部署及持續的監控與再訓練。各環節工具鏈不一,資源需求各異,且需要根據模型迭代動態調整。如何無縫協調這一復雜流程,避免“數據孤島”和流程斷點,是提升研發效率的關鍵。
- 對性能與成本的極致要求:訓練大規模模型(如大語言模型)需要極高的I/O吞吐量和低延遲的數據訪問,以避免昂貴的計算資源(如GPU集群)閑置。海量數據的長期保存、歸檔與合規管理也帶來了巨大的存儲成本壓力。
- 數據治理與安全的復雜性:在數據流動的每一個環節,都需要確保數據的質量、一致性、可追溯性,并嚴格遵守隱私保護(如GDPR)和數據安全法規。
傳統的數據管理方式,往往依賴于手動腳本、分散的工具和靜態的存儲配置,難以應對上述挑戰,導致數據科學家和工程師將大量時間耗費在數據搬運和基礎設施調試上,而非核心的算法與模型創新。
二、數據編排:定義與核心價值
數據編排(Data Orchestration)是一種新興的技術理念與平臺能力。它通過一個統一的控制平面,對跨多種環境(本地、云、邊緣)的數據、計算資源和工作流進行智能化的協調、調度與優化管理。其核心目標在于讓數據在正確的時間、以正確的形式、高效且安全地流向需要它的計算任務。
在支持AI發展的語境下,數據編排的價值具體體現在:
- 自動化與智能化的數據流水線:數據編排平臺(如Kubernetes上的KubeFlow、Airflow、Prefect等)可以定義、調度和監控復雜的多步驟AI工作流。它能自動觸發數據預處理任務,將處理好的數據直接輸送給訓練任務,并在訓練完成后自動啟動模型評估與部署,實現端到端的自動化,極大提升研發運營(MLOps)效率。
- 統一的數據虛擬化與訪問層:通過數據編排,可以構建一個邏輯上統一的“數據湖”或“數據網格”視圖,物理上分散在對象存儲、數據庫、數據倉庫中的多源數據,能夠被AI工作流以標準接口透明地訪問。這消除了數據復制和遷移的麻煩,保證了“單一數據源”的真實性。
- 性能優化與成本控制:智能編排器可以根據任務優先級和數據局部性原理,動態地將計算任務調度到離數據最近的存儲節點,或者將熱數據緩存到高速存儲(如SSD)中,從而最大化I/O性能,減少訓練時間。它還能基于策略自動將冷數據轉移到成本更低的存儲介質,實現存儲成本的整體優化。
- 增強的數據治理與安全:編排平臺可以集成數據血緣追蹤、質量監控和訪問策略管理。所有數據的流動、轉換和使用都有跡可循,并能強制執行基于角色的訪問控制和數據脫敏策略,為合規AI奠定基礎。
三、數據處理與存儲服務的協同演進
數據編排并非取代現有的數據處理(如Spark、Flink)和存儲服務(如對象存儲、并行文件系統),而是作為“粘合劑”和“大腦”,使其協同工作,發揮更大效能:
- 數據處理服務:正朝著“無服務器化”和容器化發展。數據編排平臺可以將一個數據處理任務(如特征轉換)封裝為一個容器化的微服務,按需彈性調用,并按實際使用量計費,實現極致的資源利用率。
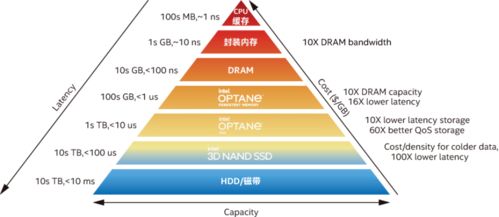
- 數據存儲服務:正從單一介質向分層、智能的存儲體系演進。通過數據編排策略,熱數據可置于高性能全閃存陣列,溫數據置于大容量硬盤,冷數據則歸檔至磁帶或云上的冰川存儲。整個分層過程對AI應用透明,實現性能與成本的最佳平衡。
四、展望:數據編排驅動AI未來
數據編排與AI的結合將更加深入:
- AI for Data Orchestration:利用機器學習算法來優化編排策略本身,例如預測數據訪問模式以進行智能預取和緩存,或自動診斷數據流水線中的瓶頸并給出優化建議。
- 面向生成式AI與大規模基礎模型:生成式AI需要處理超大規模的非結構化數據集,并進行持續的增量學習和微調。數據編排將成為管理這些持續流動、版本化的數據和模型產物的核心基礎設施。
- 邊緣-云協同AI:在物聯網和邊緣計算場景中,數據編排將負責協調邊緣設備的數據過濾、初步處理與云中心的大規模模型訓練和更新,實現高效的數據閉環。
###
數據不再是靜態的資產,而是流動的生產要素。數據編排,通過其智能化的協調與管理能力,將原本割裂的數據處理與存儲服務整合為一條高效、彈性、可靠的“數據供應鏈”,直接服務于AI模型的“智能生產線”。它解決了AI規模化應用中的核心數據瓶頸,釋放了數據潛能。因此,投資和構建先進的數據編排能力,已不僅僅是IT基礎設施的升級,更是企業贏得AI時代競爭優勢的戰略基石。AI的下一步發展,必將在高度編排化的數據沃土上,結出更豐碩的果實。